OtterScript & Operations
- 04 Sep 2023
- 6 Minutes to read
- Print
- DarkLight
- PDF
OtterScript & Operations
- Updated on 04 Sep 2023
- 6 Minutes to read
- Print
- DarkLight
- PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
OtterScript is a "Domain-Specific Language" (DSL) that's used by Otter and BuildMaster to automate deployments, orchestration, and configuration. Although it’s based on programming logic, you do not need to be a coder to use OtterScript, which offers both a text editor and a low-code visual editor.
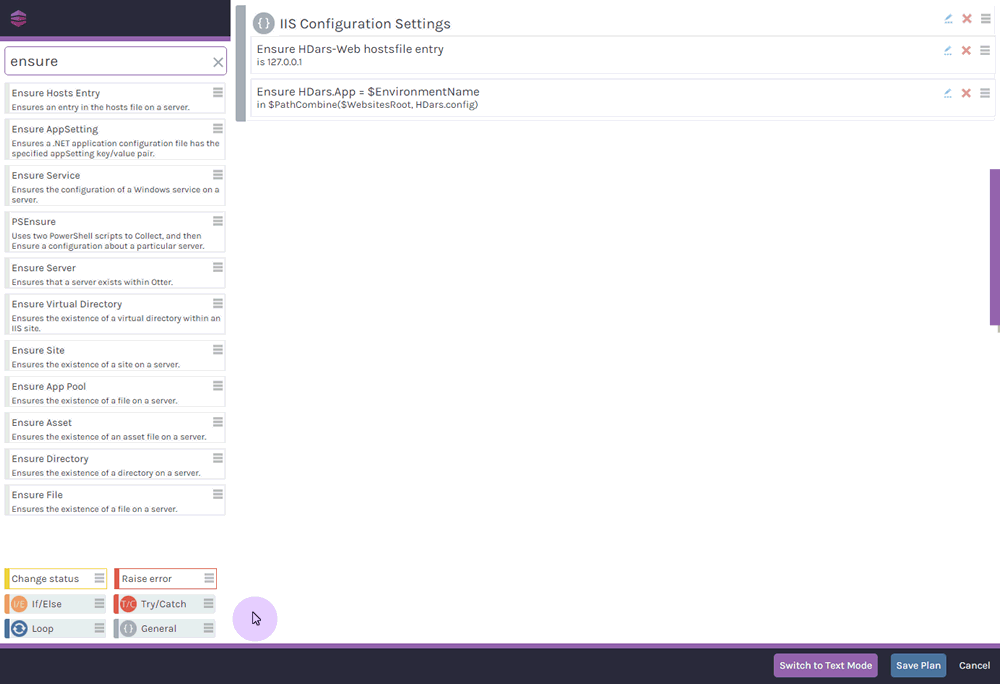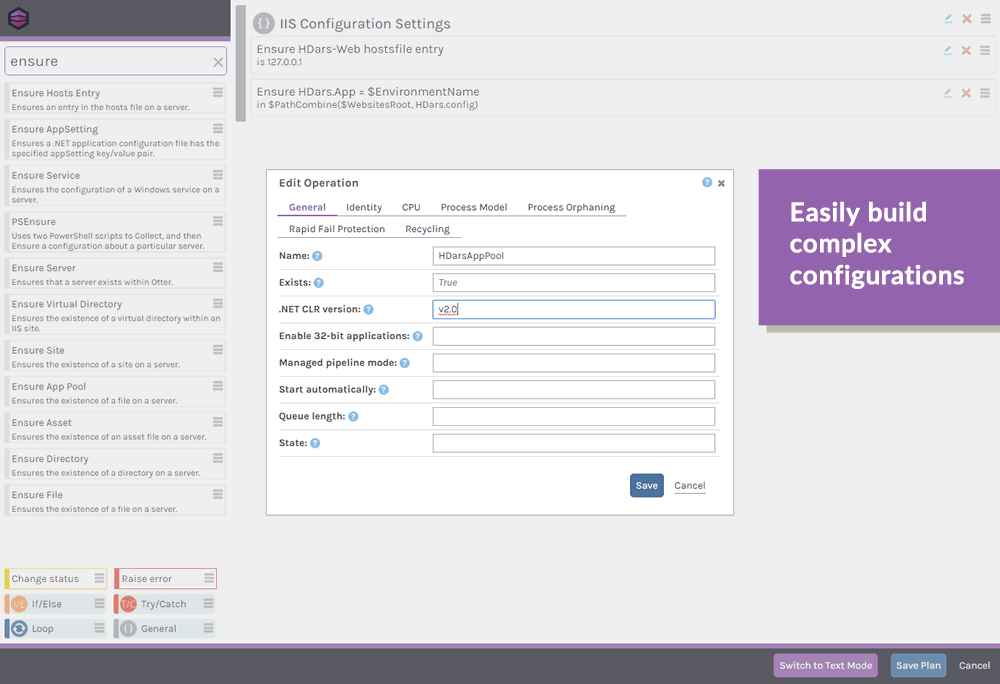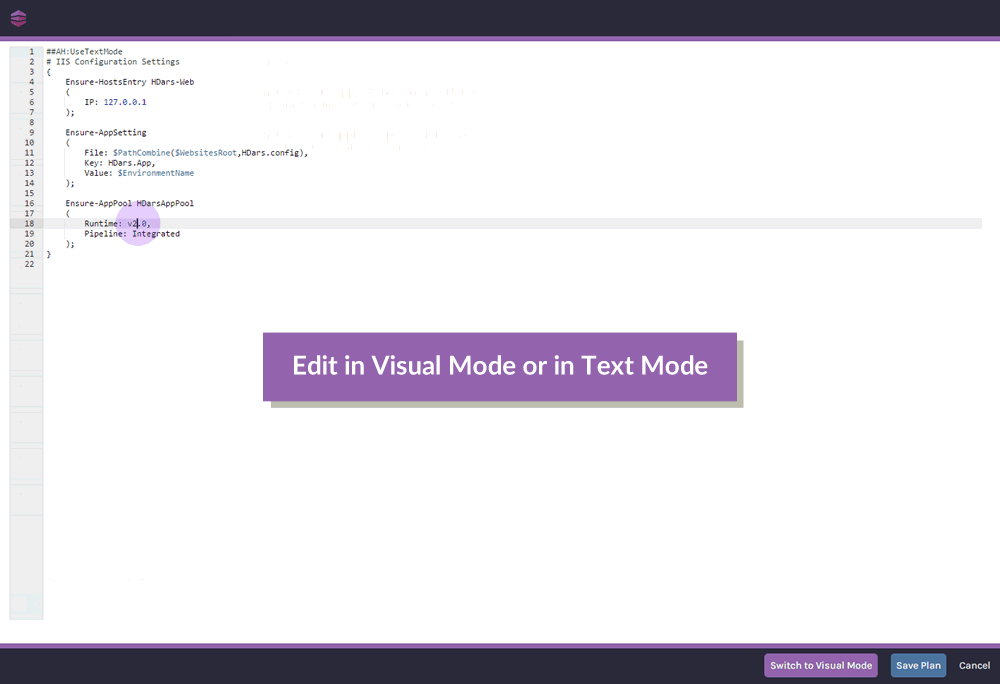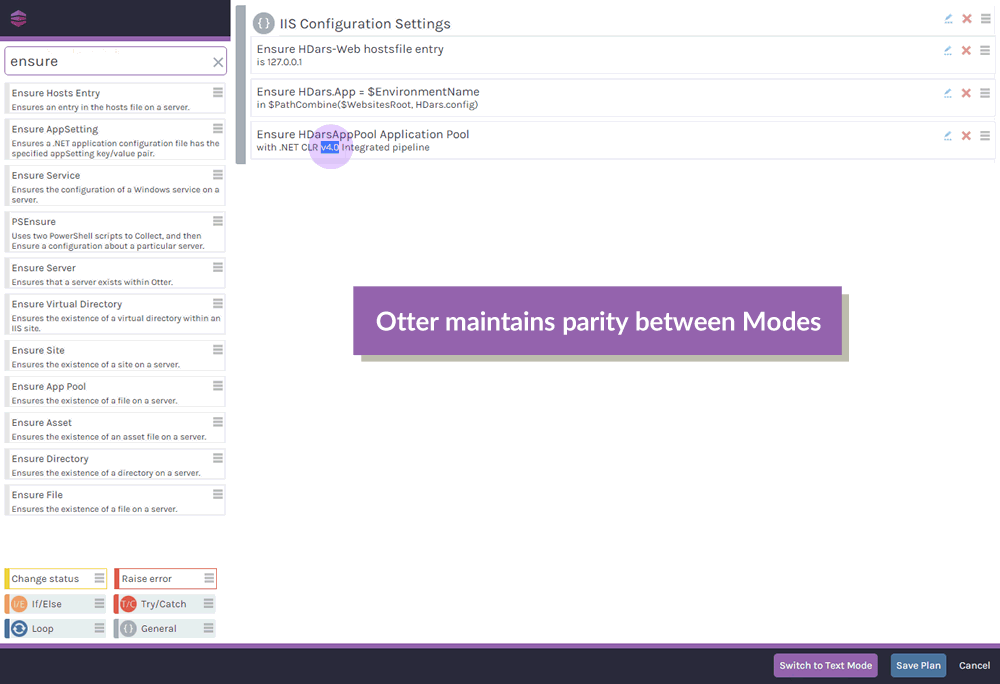
What are Operations in OtterScript?
Just about everything in OtterScript is accomplished through Operations. Whether it's the IIS::Ensure-AppPool and IIS:Ensure-Site operations that are used to configure a website on a server, or more general purpose operation like Transfer-Files that can mirror files across servers.
Otter includes a whole bunch of built-in operations, and you can even write your own using the Inedo SDK.
Regardless of where the operation comes from, there are three basic types:
- Verify – an operation that defines a desired state of configuration, gathers configuration information from a server, and if the actual and desired configuration differ, then reports drift on the server
- Ensure – an operation that can do all the things that a
Verifyoperation does, but also has the ability to change something on that server so that it matches the desired state (if desired) - Execute – an operation that does, or changes something on a server
Verify Operations and Ensure Operations are what let you describe a desired state of configuration to see if server matches that, and remediate that drift without worrying about how Otter configures a server to that state.
How do "Ensure" Operations Work?
Ensure- operations are a type of "declarative" programming. Most programmers are familiar with "procedural" (normal) programming, and have no problem jumping into OtterScript. It has all the same if/else, foreach, and try/catch blocks they're used to. But "declarative" programming can take a little getting used to.
Declarative configuration allows you to define the "desired state" of configuration, not the various steps to get there (like creating files, application pools, etc). It's a pretty powerful approach, but it's also not intuitive if you're used to "normal"programming.
Fortunately, OtterScript lets you use both in one script.
Example: Create-File vs Ensure-File
The Create-File Operation can be really simple: it just creates the file you specify and will raise throw an error if the file exists (and you don't specify Overwrite to be true).
Create-File hello-world
(
Text: hello world!,
Overwrite: true
)
There's not much more to it. The file is always created.
On the other hand, even though the Ensure-File Operation looks nearly the same, it's a bit trickier behind the scenes:
Ensure-File hello-world.txt
(
Text: hello world!
);
That's because it's an Ensure Operation, which means it will first verify that the file you describe exists (or does not exist) at the location you specify.
When checking for Configuration Drift,
Ensure-Filewill report that drift occured if the file isn't as you desire.When remediating drift, the
Ensure-Filewill create the file as specified.
Mixing Ensure & Execute Operations
You can use any type of Operation in your OtterSCript scripts, but in an ideal world, you would only use Ensure Operations when defining Desired Configuration with OtterScript, and Execute Operations in an OtterScript Orchestrations that you run with a job.
Otter's Two-stage Execution
The desired configurations that you write in OtterScript have two distinct (but related) purposes:
- Detect Drift: compare a server's desired state against the actual configuration.
- Remediate Drift: bring the server to the desired state of configuration.
Otter accomplishes this using a "two-stage execution", where the same OtterScript Configuration is run twice. The stages are:
- Collection: run the Ensure Operations, but only to gather configuration from the server, store that configuration data within Otter, and report the differences as drift.
- Execution: run the Operations (Ensure and Execute) that reported drift in an attempt to bring the server to the desired state of configuration.
This mechanism can be a bit confusing at first because the "desired configuration paradigm" is new to many people.
You must put Verify or Ensure Operations in Desired Configuration. The reason is... if you're not collecting any configuration, then you can’t execute the configuration that changed.
Execute Operations in OtterScript Configurations
When you have an Execute Operation in an OtterScript Configuration, the only time they will run is when an Ensure Operation in the same (or nested) block reports drift. This behavior may seem a bit strange at first, but it makes sense once you get used to it.
As an example, let's say that your legacy application requires that the application pool is stopped after changing the root path, and it will also experience dropped transactions if you don't wait five seconds before starting it up again. Modeling this real-world behavior is pretty much impossible using a pure-declarative syntax, but you can do it with a combination of Ensure and Execute Operations:
{
Stop-AppPool FooBarAppPool;
Sleep 5;
Ensure-Site FooBarSite
(
AppPool: FooBarAppPool,
Path: c:\websites\foobar$FooBarVersionNumber
);
Start-AppPool FooBarAppPool;
}
In this case, if the $FooBarVersionNumber changes (which will then change the root path), then Otter will detect this drift in the Collection run. When remediating configuration on a server (i.e. the Execution run), Otter will run the entire block, because a single item within it was drifted.
This behavior lets you balance ideal- and real-world configuration problems.
Runtime Behavior: Collect & Compare
Consider the following OtterScript that defines the desired configuration state of a particular server role.
Firewall::Ensure-NetFirewallRule
(
Name: FTP,
Profiles: Domain,
Port: 21,
Protocol: TCP,
Inbound: true,
Allow: false
);
Firewall::Ensure-NetFirewallRule
(
Name: SMTP,
Profiles: Domain,
Port: 25,
Protocol: TCP,
Inbound: true,
Allow: false
);
Behind the scenes, here's what Otter will do when running this OtterScript against a server during a routine collect and configuration..
- Delete Existing Configuration Items; when Otter does a configuration check on a server, all of the items under the "Current Configuration" tab are deleted. This is because they will be added back once configuration is collected from that server.
- Collect
FTPFirewall Rule from Server; when Otter encounters the first statement, it will query the server's firewall configuration for a rule named "FTP". This is a lot like runningGet-NetFirewallRule -name FTPin PowerShell. - Add
FTPRecord to Otter; depending on whether there is or isn't a rule named "FTP" on the server, Otter will record the results in one of two ways:- Rule Doesn't Exist; if no such firewall rule exists, then an "FTP" Current configuration record is added, but it's set to "doesn't exist" and "Drifted". It's drifted because the desired configuration defines it as existing
- Rule Does Exist; if there is a firewall rule, then "FTP" Current configuration record is added, and then
- all properties defined on the operation (Profiles, Port, Protocol, Inbound, Allow) are added to the record
- each property is then compared against the desired value (is it in the Domain profile? Is it for Port 21? And so on)
- If any property doesn't match, then the configuration is drifted.
- Collect
SMTPFirewall Rule from Server; this follows the same logic from above - Add
SMTPFirewall Rule to Otter; this also follows the same logic as "FTP"
Note that Otter will only collect and compare the configuration items and properties that are specified in the OtterScript. This keeps it easy to keep track of the important pieces of config.
For example, based on the above Otterscript, Otter would not collect an "HTTP" rule unless it's part of the desired configuration. If a rule like "FTP" rule had an "EdgeTraversalPolicy", then HTTP wouldn't be collected, because it's not part of the desired configuration.
Server Roles and OtterScript
To compare a server's current (actual) configuration against the desired configuration, Otter generates a single, desired configuration OtterScript from all of the roles assigned to that server.
For example, if a server is assigned the secure-ports and profitcalc-app roles, then the generated OtterScript would look just like you copy/pasted the OtterScript from those two roles into a single script.
It can get a bit more complicated once you start defining server role dependencies. You can see this generated plan on the "Desired Configuration" tab of a server.
Was this article helpful?

